

Hadoop入门教程(九):本地搭建 Hadoop 开发环境
上一篇我们大致讲了 HDFS,从本节以后我们将通过编程写代码的方式开始使用 Hadoop 为我们服务,所以需要先搭建本地的 Hadoop 开发环境。如果阅读了前面的文章并在虚拟机中成功搭建了Hadoop,那么在本地搭建是易如反掌的,如果您还没搭建过或者没阅读过前面的文章,建议先阅读前面的文章。
进入阅读
Hadoop入门教程(八):DataNode 工作原理
当 DataNode 启动后会向 NameNode 注册自己,并按周期(1小时)上报自己所有 Block 数据块信息。每3秒还会和 NameNode 传递心跳包,心跳包中包含了给 DataNode 的命令,如果超过10分钟没有收到 DataNode 的心跳,就认为该节点不可用。
进入阅读
Hadoop入门教程(七):HDFS 数据读写流程
上一篇我们已经可以通过编程的方式操作 HDFS 了,但这一切背后在Hadoop集群里发生了什么呢,本篇文章简单介绍一下 HDFS 的读写流程。
进入阅读
Hadoop入门教程(六):Hadoop API 使用编程的方式操作 HDFS
上一篇讲了使用 Shell 命令操作 HDFS,但实际中我们肯定不可能一直手动操作,还是需要通过编程实现自动化的,所以本文将带你熟悉一下使用 Java 编程控制 HDFS 中的文件。
进入阅读
Hadoop入门教程(五):HDFS 分布式文件系统
HDFS是指 Hadoop Distributed File System,Hadoop分布式文件系统。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。
进入阅读
Hadoop入门教程(四):Hadoop 完全分布式集群环境
上一篇我们尝试了伪分布式的安装搭建,但真正使用的是分布式集群,所以这才是重点,本文章将使用三个节点来安装最小的Hadoop集群,体验完全分布式的环境。
进入阅读
Hadoop入门教程(三):Hadoop 单节点本地运行与伪分布式
因为是入门学习,很多同学的电脑性能不具备集群环境的要求,我们先了解一下 Hadoop 单节点运行模式,以便您可以使用 Hadoop MapReduce和 Hadoop 分布式文件系统(HDFS)快速执行简单的操作。本节内容主要是带新手体验一下 Hadoop 的案例,相当于 Hello World 案例,揭开 Hadoop 神秘的面纱。
进入阅读
Hadoop入门教程(二):Hadoop 的安装教程
在开始我们的 Hadoop 之旅前,我们需要先学会安装 Hadoop ,在后面我们将使用多个 Hadoop 节点进行试验和学习,本文将带你安装 Hadoop,这是非常简单的。
进入阅读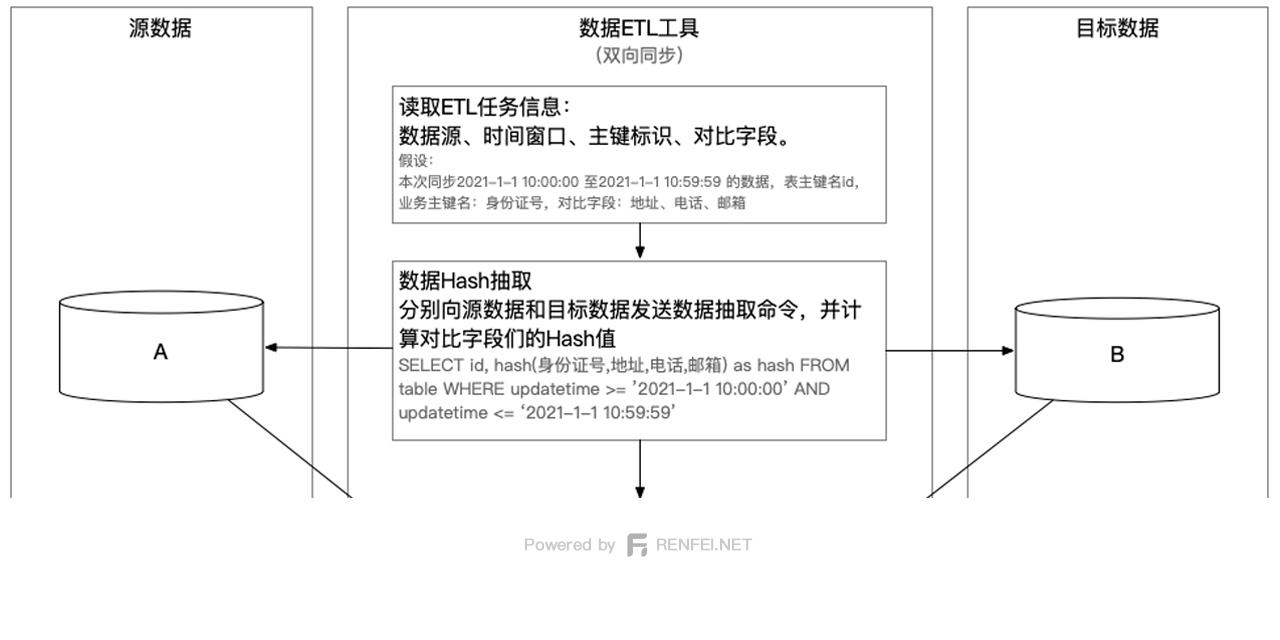
关于更正《大数据ETL技术中的数据抽取方法》
原文中第一次对比求出了 CuB 和 CuA 两个补集,第二次拉取真实数据进行二次比对,根据在实际生产环境汇总应用时发现,在第二次比对中拉取原文数据是可以省略的,所以更正了上一篇文章的ETL操作步奏。
进入阅读
Hadoop入门教程(一):Hadoop 是什么 Hadoop 由什么组成
在上一大章节我们讲了大数据仓库的概念,我们了解了数仓的建设思想,接下来我们就开始让我们的思想慢慢变为现实,承载这一切的基础就是 Hadoop 生态圈中的各种大数据组件,慢慢形成我们的大数据仓库和平台。
进入阅读
-
ETH
renfei.eth
-
renfei.sol
-

- 前后端分离项目接口数据加密的秘钥交换逻辑(RSA、AES)
- OmniGraffle 激活/破解 密钥/密匙/Key/License
- 人大金仓 KingbaseES V8 R3 安装包、驱动包和 License 下载地址
- Parallels Desktop For Mac 16.0.1.48911 破解版 [TNT]
- Redis 未授权访问漏洞分析 cleanfda 脚本复现漏洞挖矿
- CleanMyMac X 破解版 [TNT] 4.6.0
- OmniPlan 激活/破解 密钥/密匙/Key/License
- Parallels Desktop For Mac 15.1.4.47270 破解版 [TNT]
- Sound Control 破解版 2.4.2
- 向谷歌搜索引擎主动推送网页的教程 Google Indexing API 接口实现
- 博客完全迁移上阿里云,我所使用的阿里云架构
- 微软确认Windows 10存在bug 部分电脑升级后被冻结
- 大佬们在说的AQS,到底啥是个AQS(AbstractQueuedSynchronizer)同步队列
- 比特币(BTC)钱包客户端区块链数据同步慢,区块链数据离线下载
- Java中说的CAS(compare and swap)是个啥
- 小心免费主题!那些WordPress主题后门,一招拥有管理员权限
- 强烈谴责[wamae.win]恶意反向代理我站并篡改我站网页
- 讨论下Java中的volatile和JMM(Java Memory Model)Java内存模型
- 新版个人网站 NEILREN4J 上线并开源程序源码
- 我站近期遭受到恶意不友好访问攻击公告