
教程索引目录请访问:《大数据技术入门级系列教程》
上一篇我们尝试了伪分布式的安装搭建,但真正使用的是分布式集群,所以这才是重点,本文章将使用三个节点来安装最小的Hadoop集群,体验完全分布式的环境。
先决条件
首先此处只讲 Hadoop,不再赘述 Linux 相关的知识点,需要您熟悉使用 Linux,并按照前面的教程安装配置好 Hadoop 环境,最少准备 3台 Linux 进行实验学习。除了前面之前的教程,到此文章之前,我还给 3 台机器配置了 SSH Key 免密登陆,这 3台机器相互可以免密登陆,这个需要你自己配置一下,不再赘述。
集群设计
首先,集群的机器数量应该是奇数,所以最小的是3,按照奇数要求就是 3、5、7、9,不要弄成偶数哦,主要是为了leader选举算法,这不多说,只将Hadoop。
在集群中我们需要以下节点:NameNode、SecondaryNameNode、DataNode、ResourceManager,NodeManager和DataNod运行在一起。使用三个节点来搭配安装,我的设计如下:
- n1.renfei.net:NameNode、DataNode、ResourceManager
- n2.renfei.net:SecondaryNameNode、DataNode、NodeManager
- n3.renfei.net:DataNode、NodeManager
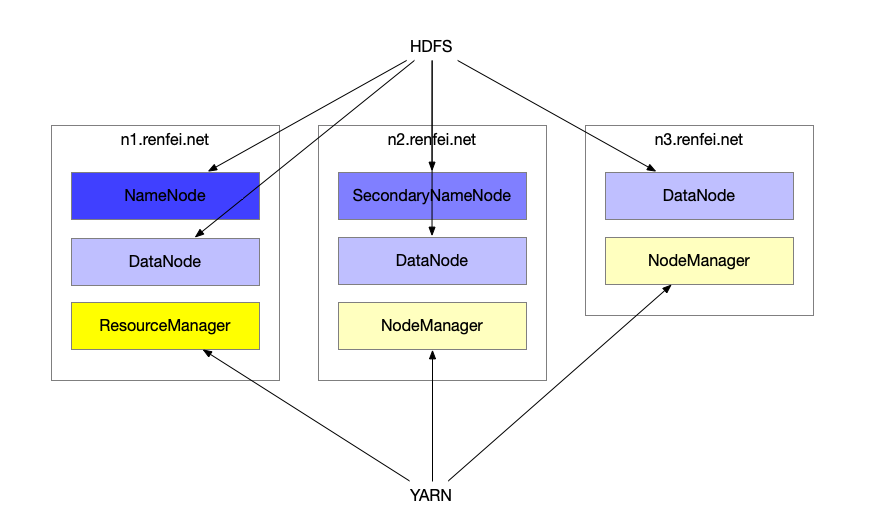
域名可以通过修改 /etc/hosts 实现。也就是 n1.renfei.net 主要负责 HDFS,n2.renfei.net 主要负责 Yarn,三台机器上全部负责存储,结构如下图所示:
配置修改
下面的配置文件修改在三台机器上内容都一样,我在这里只写一遍,其中在env.shh配置的 JAVA_HOME 变量根据自己的路径去配置,在我的案例中我把 JDK 解压到了 /opt/module/jdk1.8.0_281。
配置 core-site.xml
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://n1.renfei.net:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.10.1/data/tmp</value>
</property>在这里我们指定谁是 NameNode,以及运行时产生文件的存储目录
配置 hadoop-env.sh、hdfs-site.xml
修改 hadoop-env.sh 中 JAVA_HOME 为自己的路径。再配置 hdfs-site.xml:
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>n2.renfei.net:50090</value>
</property>在这里,我们指定了 dfs.replication = 3,这个是副本数,也就是文件会复制几份,如果是3,那么就会复制到三个节点上进行数据冗余。
配置 yarn-env.sh、yarn-site.xml
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>n1.renfei.net</value>
</property>
<!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>配置 mapred-env.sh、mapred-site.xml
修改 mapred-env.sh 中 JAVA_HOME 为自己的路径。再配置 mapred-site.xml:
将mapred-site.xml.template复制一份为mapred-site.xml
<!-- 指定MR运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>n1.renfei.net:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>n1.renfei.net:19888</value>
</property>配置 slaves
配置 /opt/module/hadoop-2.10.1/etc/hadoop/slaves,将我们的节点都写进去:
n1.renfei.net
n2.renfei.net
n3.renfei.net注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
启动集群
此处在 n1.renfei.net 群起集群需要配置 SSH Key 免密登陆,请先配置集群的免密登陆。
如果集群是第一次启动,需要格式化NameNode(注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据),格式化的命令在上一篇已经讲过了,请回顾上一篇的内容。
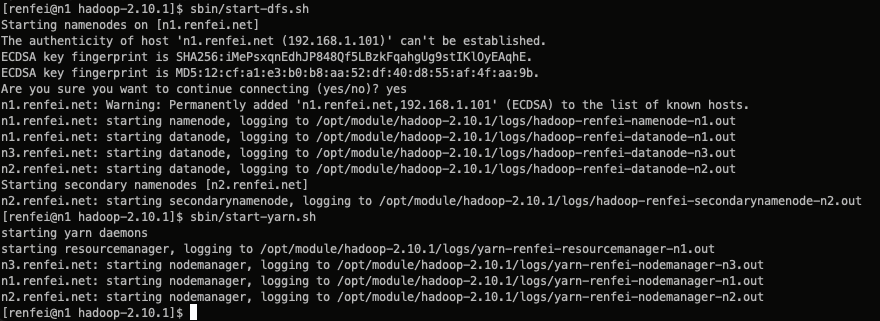
sbin/start-dfs.sh
sbin/start-yarn.sh注意:NameNode和ResourceManger如果不是同一台机器,不能在NameNode上启动 YARN,应该在ResouceManager所在的机器上启动YARN。
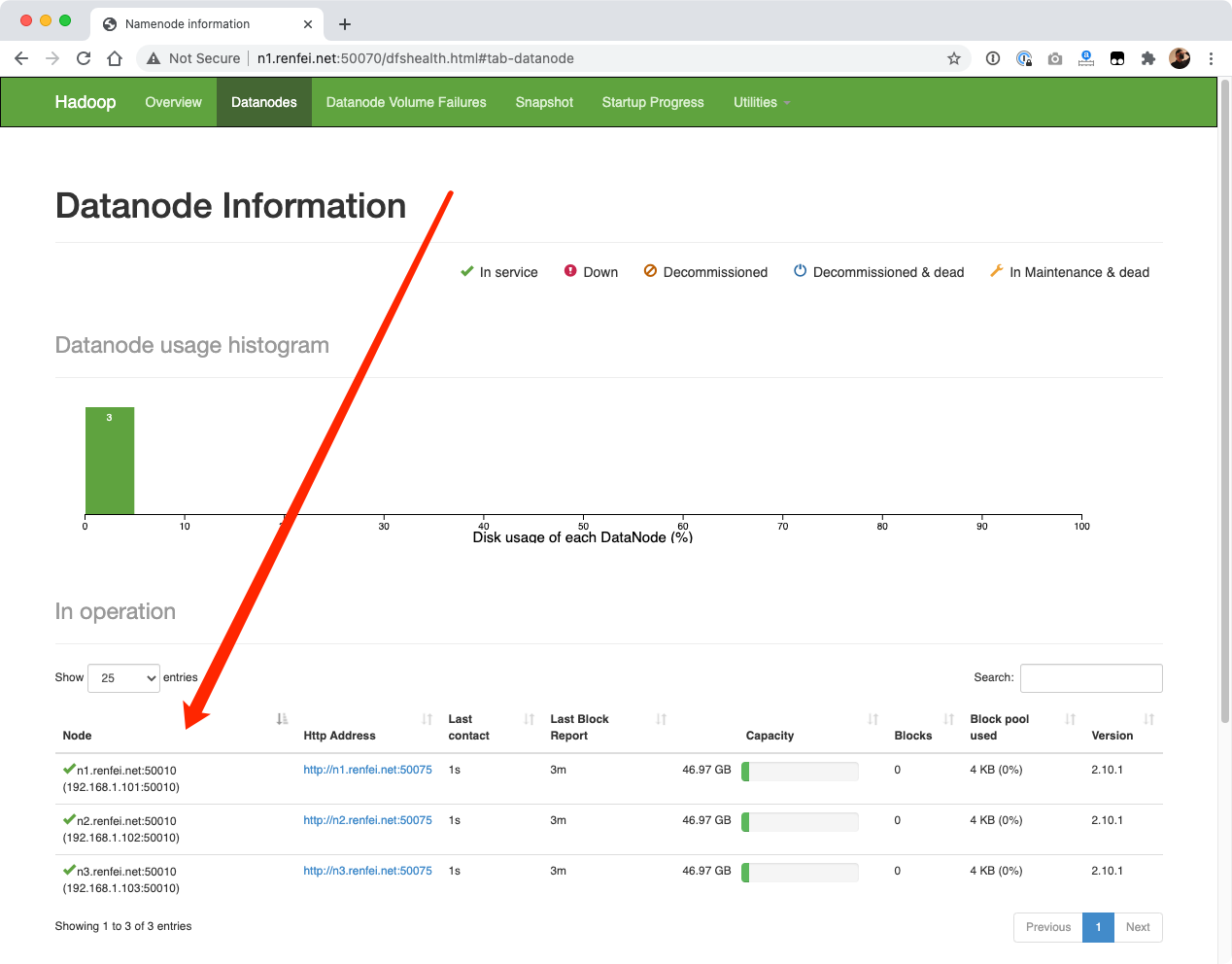
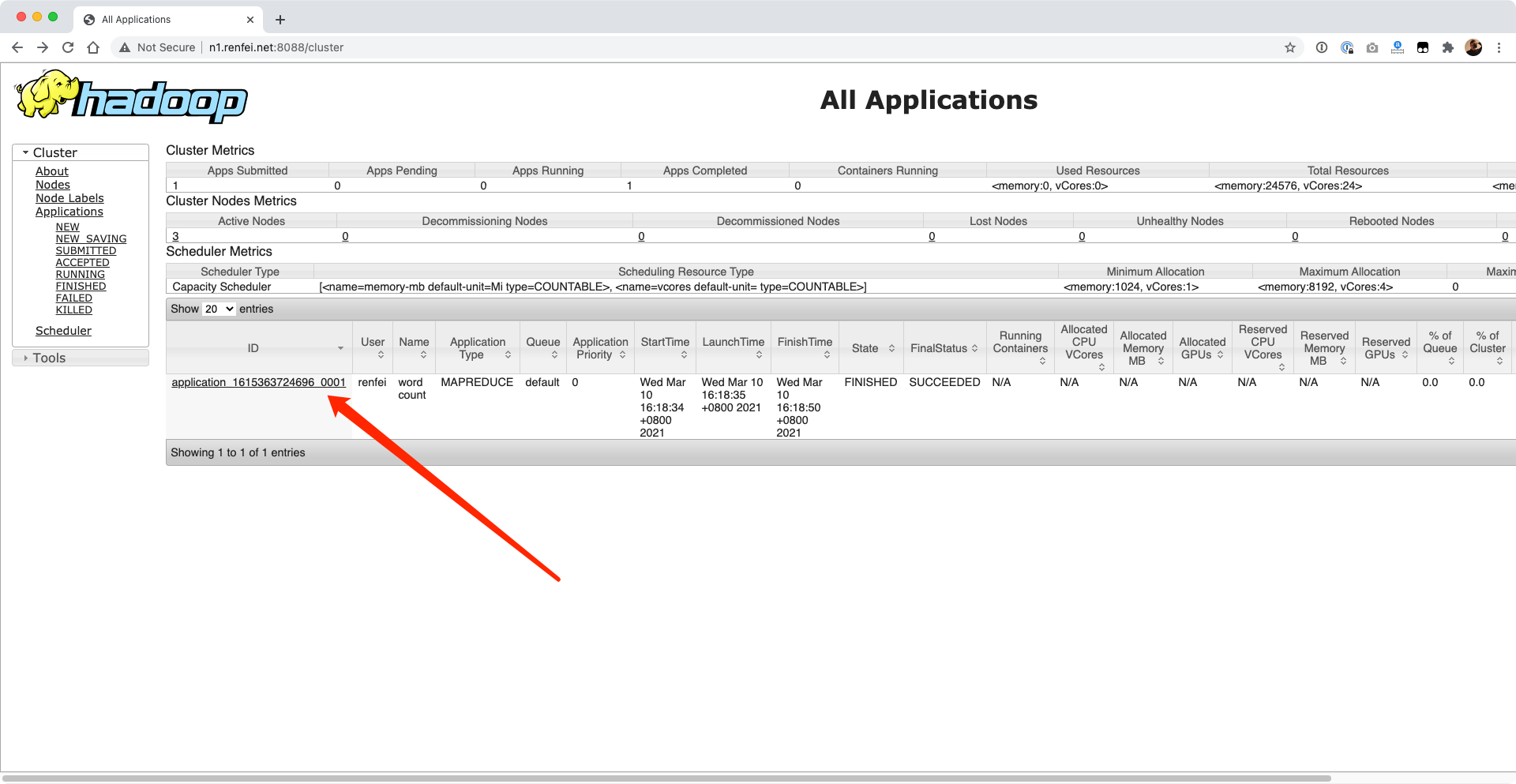
测试使用集群
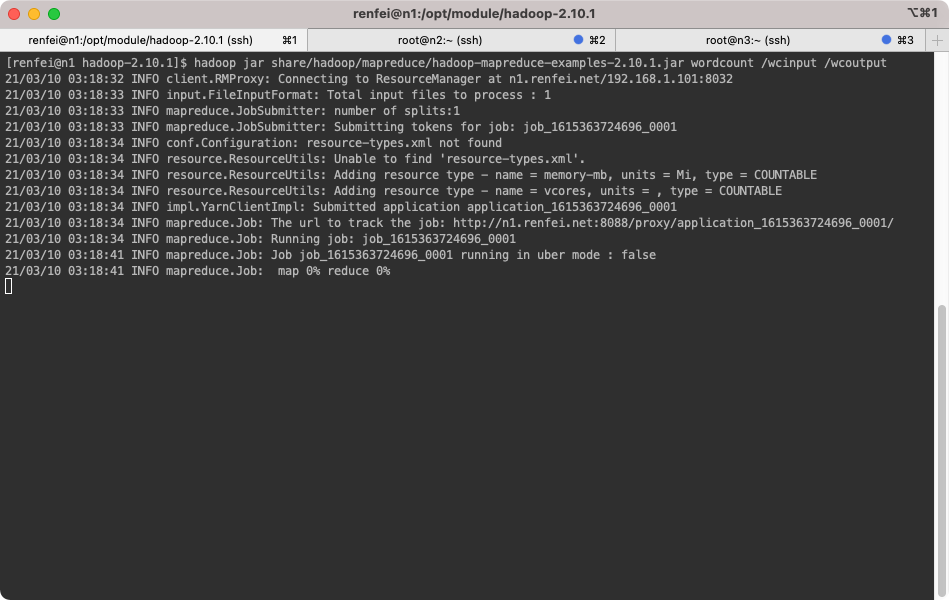
在上一篇文章中我们体验了伪分布式模式中的 WordCount 案例,现在还使用WordCount案例进行集群测试,如果不知道怎么运行 WordCount 案例,请回顾上一篇文章。
结尾
到这里你已经拥有一个自己的 Hadoop 集群了,接下来我们讲关注重点转移到 Hadoop 的核心:HDFS、MapReduce。