本文是对《大数据ETL技术中的数据抽取方法》的更正补充说明,其中有一些不必要的操作可以省略。
原文中第一次对比求出了 CuB 和 CuA 两个补集,第二次拉取真实数据进行二次比对,根据在实际生产环境汇总应用时发现,在第二次比对中拉取原文数据是可以省略的,所以更正了上一篇文章的ETL操作步奏。
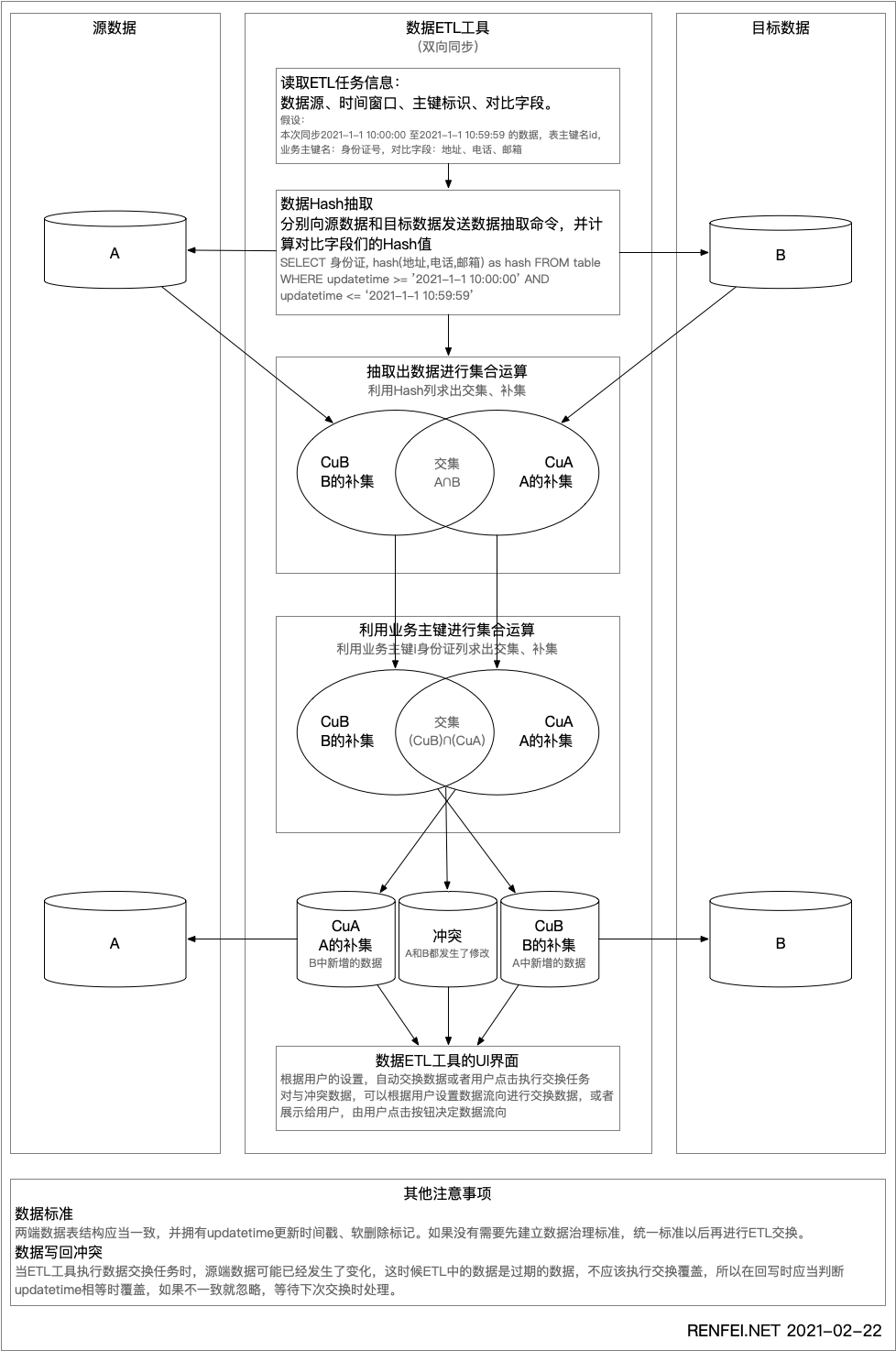
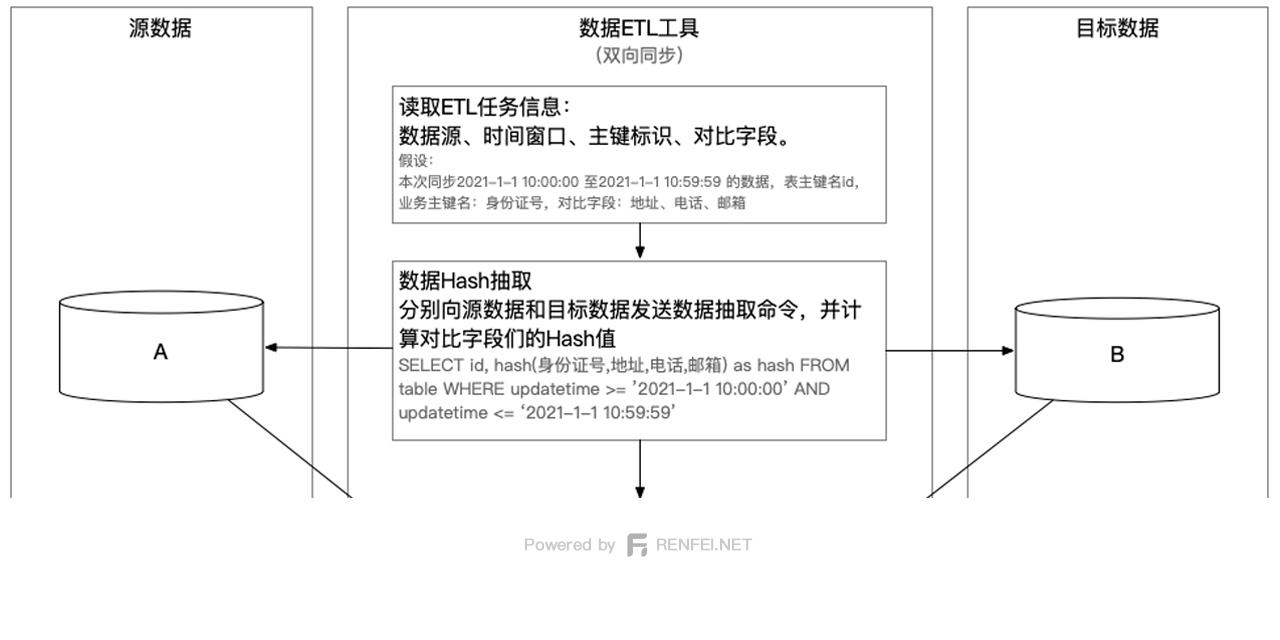
第一步:抽取数据 哈希 Hash
在第一步抽取数据 哈希 Hash 时,就应该传入业务主键,例如:id 或者 身份证号,在求 哈希 Hash 时直接带入:
SELECT 身份证, hash(其他字段们) FROM table;将得到两端的 身份证, hash 两个集合 A、B,将两个集合使用 hash 进行比对,求出 CuB 和 CuA 两个补集。
第二步:根据业务标识求补集和交集
在第一步求出 CuB 和 CuA 两个补集,再将两个补集求交集和补集,这个时候不用 hash,而是用业务标识:身份证号,此时得到的交集就是冲突数据,身份证号一直但数据不一致,两个补集还是各自的补集。
所以我们就得到了三个集合:CuB、CuA、冲突集合
第三步:将三个集合向下传递给对应的处理服务
CuB 和 CuA 两个补集可以直接拉取数据进行交换,冲突集合可以根据用户设置来选择:显示冲突等待用户决策、A覆盖B或者B覆盖A。
关于效率提升局部敏感哈希请移步:《大数据ETL技术中对数据进行局部哈希对比优化对比速度》