
教程索引目录请访问:《大数据技术入门级系列教程》
在上一篇数据仓库分层设计中,我们还提到了各个层除了原始表还进行了一些加工,在加工的时候还提到了事实表、维度表,本文带你粗略的理解一下事实表、维度表,数据模型中的星型模型、雪花模型。
事实表、维度表有的时候很模糊,造成了在数仓建设中一些不符合标准。
事实表(fact)
首先什么是事实呢?事实就是描述一个事物真实的发生了,一个用户把商品加入购物车这个事件在数据库中就是一条记录,这个就是在数据库汇总描述了一个事实。
事实,也分为三种,可加型事实,半可加型事实,不可加型事实。
- 可加型事实,指的是在所有维度加起来都有意义的度量。
- 半可加型事实,指的是在特定维度下加起来有意义,另一些维度下加起来无意义的度量。
- 不可加型事实,是指在所有维度下,加起来都没有意义的度量。
比如我们银行卡账单里的流水,无论是按时间求和还是按购物场所求和,怎么求和都有意义,是某个维度下的流水总数,这个就是可加型事实。
同样是我们的银行卡账单,如果你把余额都加起来,只有某个时间点把所有用户的余额都加起来才有意义,如果是按购物场所将用户余额求和,那么得出的数字什么意义也没有,这个就是半可加型事实。
同样是我们的银行卡账单,里面的卡号,无论你在什么维度下求和都没有意义,就是不可加型事实。
维度表(dimension)
什么是维度,维度是看待事实的角度。
同样是上面的银行卡账单数据,我们可以用时间角度来看,也可以从消费场所来看,也可以从消费渠道来看,这些就是他们的维度数据,比如消费渠道里可能有支付宝、微信、京东、线下POS、线下ATM,这些都是这个事实的维度。
星型模型和雪花模型
既然我们对数据进行了拆分,分为事实表和维度表,那么他们的模型结构怎么设计呢,这里就需要提一下星型模型和雪花模型。
星型模型
正如其名,这个结构像是一个星星,中间是事实表,周围围绕这各个维度表,通过外键相关联,在下方我画了一个示意图,星型虽然很快就可以取到我们需要的数据,但是其中会有很大的数据冗余,比如地区维度表,就需要存储 A省B市C区D街、A省B市E区F街,其中A省B市出现了冗余
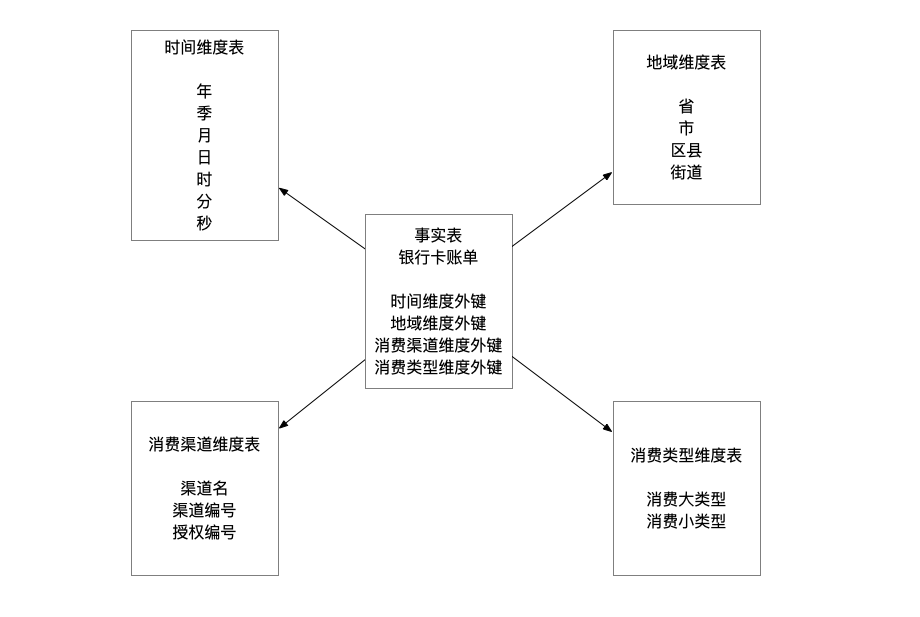
雪花模型
雪花的样子大家应该都见过吧,从中间向四周发射,每个分支上又发射出多条线,雪花模型和雪花非常像,中间是事实表,周围围绕这各个维度表,维度表周围可能还有一圈维度表,在下方我画了一个示意图,也就是说当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上,就是雪花模型。
雪花模型是对星型模型的扩展,它对星型模型的维表进一步层次化,原有的各维表可能被扩展为小的事实表,例如我下面的示意图,将地区维度表再分解为省、市、区县、街道维度,这样就降低了数据冗余程度,但想要拿到地区还需要关联多个维表,提高了复杂性。
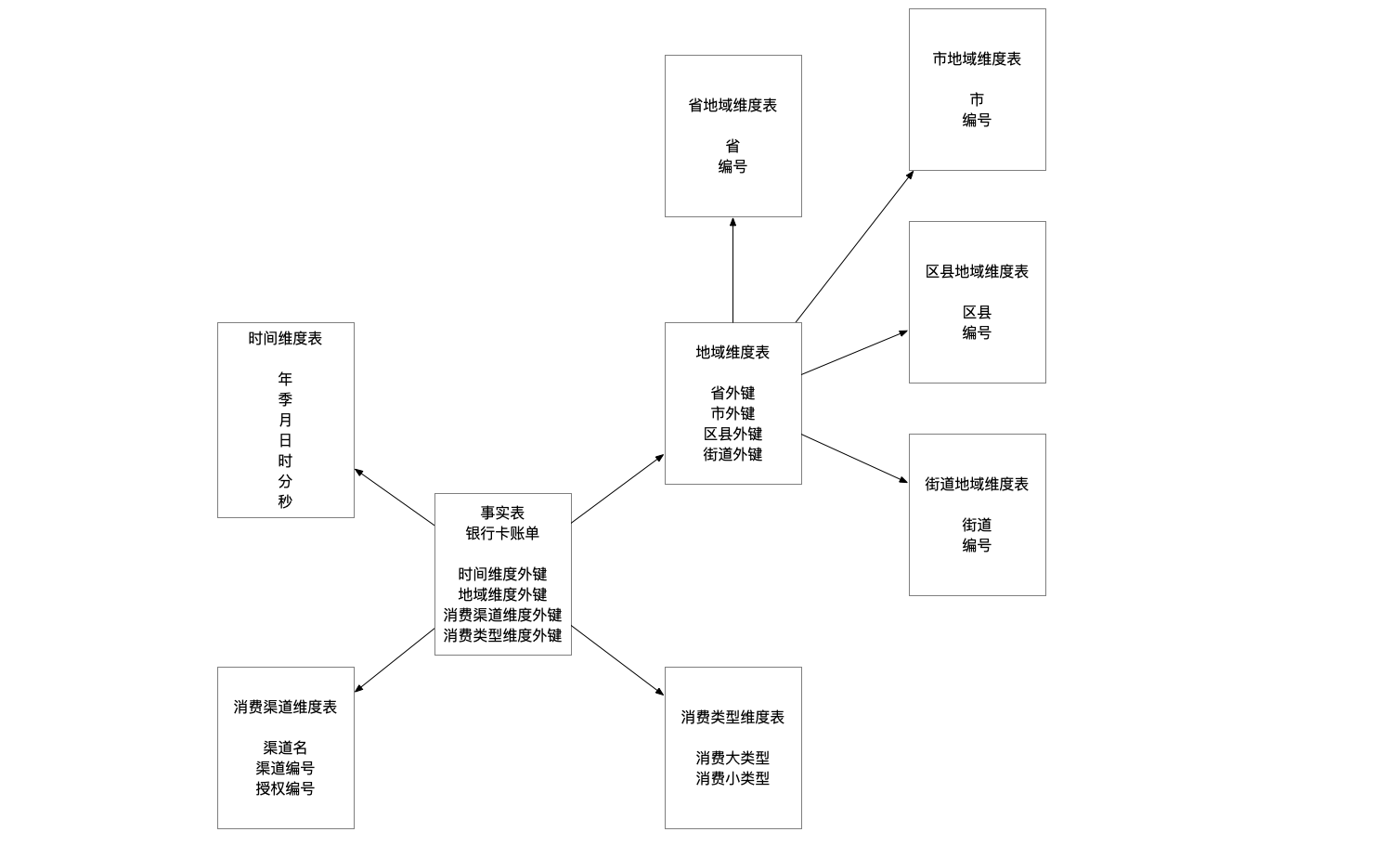
总结
查询性能角度来看雪花型模型更有利于度量值的聚合,因此性能要高于星型模型。模型复杂度角度来看星型模型更简单方便处理。层次结构角度来看雪花模型更贴近真实系统,结构关系清晰。存储角度来看,雪花模型具有关系数据模型的所有优点,不会产生冗余数据,而相比之下星型模型会产生数据冗余。
到底用哪个没有标准答案,需要你在实际生产环境中去取舍,不过一般星型模型用的多,查询效率高,硬盘已经不贵了可以忍。